




As distributed systems get more and more, well, distributed, the potential for miscommunication between myriad services rises. An increased latency of 0.5 seconds might have no consequences for component A, or even B or C, but it could be a major problem for component Z.
The issue here is that – with so many services and components – and many more interactions between them, it’s simply not practical to set up normal testing for every conceivable scenario.
So what do you do?
The answer is chaos engineering.
In this piece, we cover:
- What chaos engineering is
- The history of chaos engineering – from Netflix to beyond
- The principles of chaos engineering
- What chaos engineering services are available today
What is chaos engineering?
Put simply, chaos engineering means introducing chaos into your system to find weaknesses so they can be guarded against.
This chaos can take many forms, from randomly switching off individual instances to dropping whole AWS regions, but CEO and Co-founder of Gremlin Kolton Andrus said it best when he compared chaos engineering to a vaccine.
In both cases, you’re introducing a controlled form of danger into a system with a view to strengthening the system’s response.
Chaos engineering tools and methods are varied, but they all follow the general pattern of introducing some unexpected scenario to a system in a controlled manner and generating insights as a result.
The history of chaos engineering, from Netflix to beyond

Chaos engineering at Netflix:
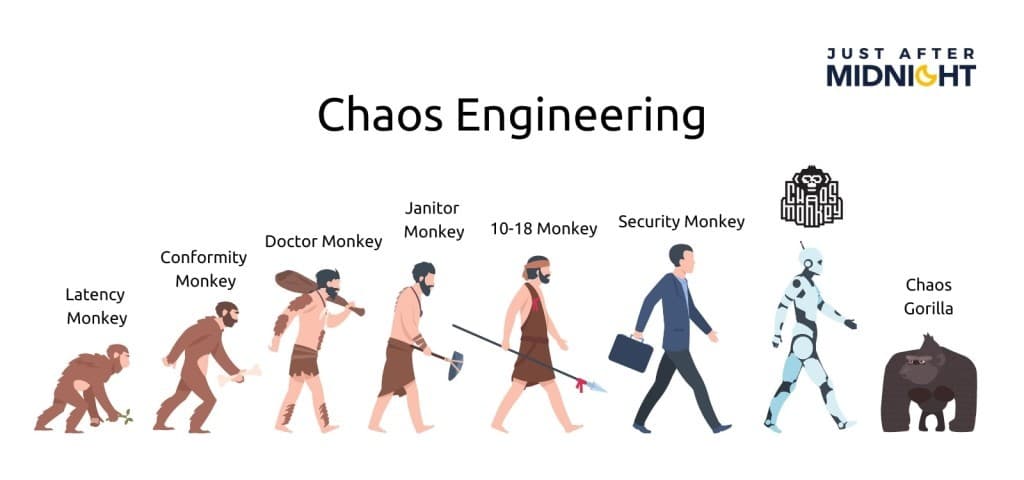
In 2011, Netflix released a blog detailing a new and innovative concept: Chaos Monkey. This followed a move from physical servers to AWS architecture, and from postal DVDs to streaming.
In short, the team needed a way to make sure their new delivery system was as resilient as possible.
Chaos Monkey achieved this by randomly terminating instances, and letting the team see how they would fare.
The name ‘Chaos Monkey’ evolved from this concept: a wild monkey roaming loose in your data centres, smashing servers and chewing through cables as it went.
Later, greater apes like Chaos Kong switched off whole AWS regions, while Chaos Gorilla contented itself by knocking over availability zones, but Chaos Monkey was the very first chaos tool.
Evolution of Netflix’s ‘Simian Army,’ Chaos Monkey and more…
Beyond Netflix
In 2014, Netflix released the source code for Chaos Monkey on Github. And though the team continued to expand the ranks of the Simian army, other companies have since stepped in to offer chaos engineering tools on a broader scale.
This has led to the coining of the term FaaS, or failure as a service, not to be (though easily) confused with function as a service.
The Principles of chaos engineering

Chaos engineering is, at heart, a scientific method. And as such, it breaks down into a series of steps (or principles) that lay out the conditions for a rigorous experiment.
1. define your system’s normal state
When you carry out a chaos experiment, you’ll create an experiment group and a control group – just like in a laboratory.
To create the control group, you first need to identify a few key metrics and then define what their ‘normal’ range is.
One example from Netflix was the rate at which users were pressing the play button, i.e. lots and lots of clicks probably = videos stuck on a load screen.
Once you’ve done this, and got a good handle on those metric’s thresholds when your system’s healthy, you can create your experiment group and introduce some chaos.
2. Introduce ‘realistic’ chaos
As we’ve already covered, chaos tools can introduce the unexpected in a lot of different ways, but it pays to configure them so that the chaos introduced falls on the possible end of unlikely.
It could be random server failures, traffic spikes or latency, whatever problems you might realistically encounter.
3. Minimise the blast radius
As the name suggests, this means containing the potential harm to customers as much as possible. As you’ll see in the next point, you’ll often be testing in production, which means you’ll want to have your team prepped for incident response and have a sure-fire way of both shutting the experiment down and limiting its effects to a small area.
4. Test in production
Although you might start off testing in staging, the whole point of chaos engineering is seeing how your real, live system responds to the unexpected, so testing in staging is often the goal.
5. Automate continuous chaos
To gather truly deep system knowledge and build workable responses to problems, you’ll want to automate your chaos experiments to run continuously. This will allow you to learn more and more about your system and identify potential issues with new features.
Chaos engineering services (chaos engineering with AWS, MSPs and other providers)

Chaos Engineering on AWS – is there such a thing as AWS Chaos Monkey?
It’s perfectly possible possible to approximate your own Chaos Monkey using AWS services. Here AWS’s own Adrian Hornsby explains one approach using AWS SSM Run Command. But it’s also possible to run other provider’s chaos tools in your AWS infrastructure. Your approach will probably depend on your in-house resources – whether you handle your chaos experiments yourself or enlist the services of an MSP.
Chaos Engineering on Azure
While the Azure team continue to refine their approaches to failure injection and Chaos, many MSPs – including yours truly – offer chaos engineering services for Azure Infrastructures.
In-house or partner-up?
This really comes down to whether or not you have the capability. If you have, and you like to keep things in-house, that’s an option. You can also checkout specialist teams who live and breath chaos, but the plus of going with a more well-rounded MSP is that they’ll have the deep knowledge of your stack already that a specialist team will have to acquire – it’s a balancing act.
The takeaways:
- As distributed systems become more complex, you need a way of testing them for various interactions and scenarios
- Chaos engineering fills this role, introducing random problems to help identify system weaknesses
- Chaos engineering was pioneered by Netflix back in 2011, but has since evolved into much much more
- When carrying out chaos engineering, it pays to stick to the core principles: define your system’s normal, introduce ‘realistic’ chaos, minimise the blast radius, test in production, reach automated and continuous chaos
- There are many ways to access chaos engineering services, either DIY or through a partner – and each comes with pros and cons.
If you’re looking to sure-up a complex distributed system, just get in touch.




