




What’s this all about?
As tech stacks get taller and more wobbly, the complexity everyone has to deal with increases – see the rise in job titles like full-stack developer, full-stack engineer, full-stack xxx.
In some areas, this inflating complexity is well catered for. See above job roles. But one place lacking clear answers to this question is support, i.e
- What is full-stack support?
- What is infrastructure+app support?
So, with uptime a more pressing concern than ever, we thought we’d answer the question – what is full-stack 24/7 support and why should agencies care about it?
Excuse me, what’s a tech stack?
A tech stack, or technology stack, or plain stack is the sum total of the technology used to power any one application.
Examples of tech stacks used by big players (Amazon and Facebook)
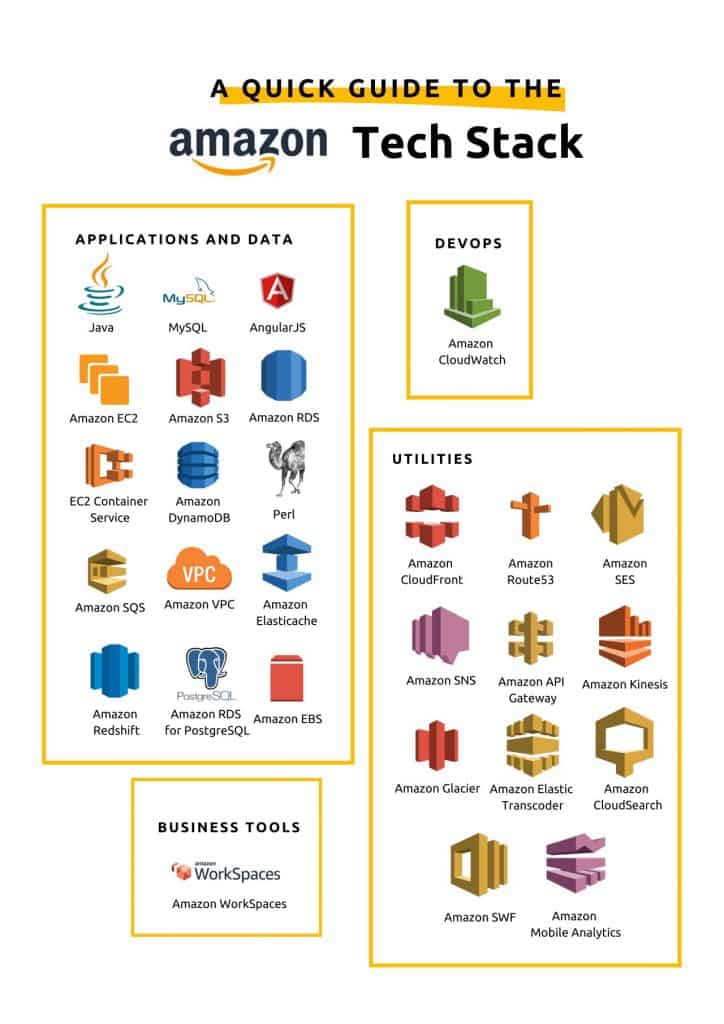
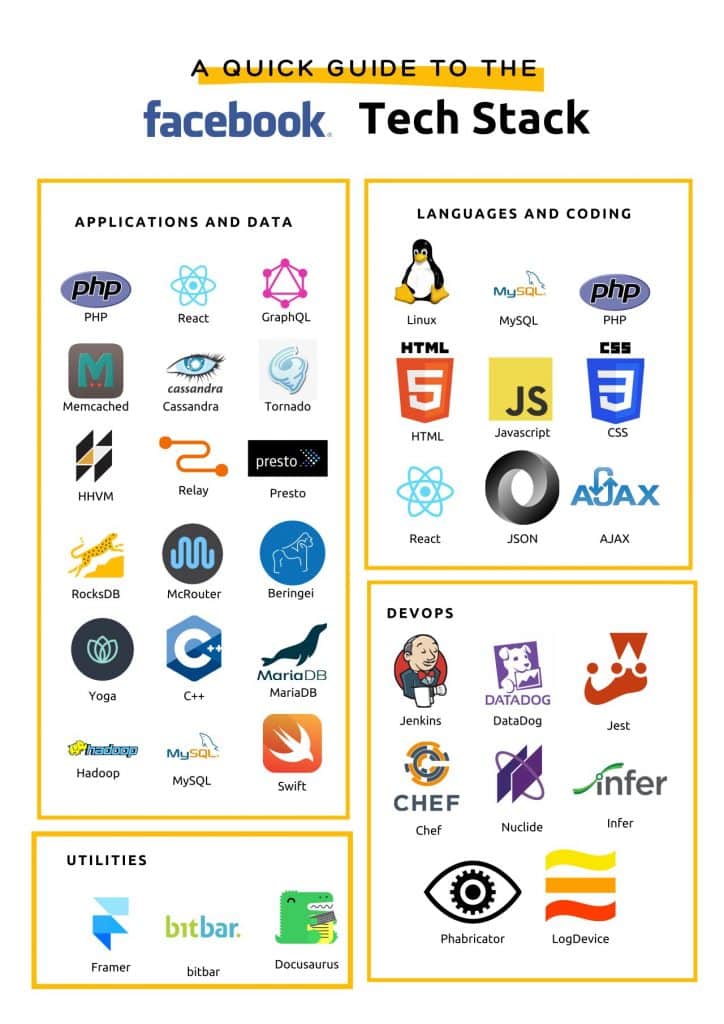
(representation of tech stacks based on research from mixpanel)
As you can see, A LOT goes into powering these applications. And it’s a far cry from the time when tech stacks consisted of a handful of services, often locked to a single vendor.
Why have tech stacks become so complex?
Put simply, because they can.
With advances in APIs, and XaaS (anything as a service) it’s become much easier to incorporate all kinds of services and tools into a solution.
The upside of this, of course, is that you can choose from best-of-breed services, and generally have a lot more flexibility and functionality when putting an application together.
The downside, as mentioned, is increased complexity.
Why should I care?
With uptime being a fundamental requirement, and stacks getting more complex, the big hole that opens up is 24/7 full-stack support.
Without this, you can have issues arising out of all kinds of interactions between different services and teams:
- A tiny part of your or a client’s solution nobody knows anything about which crashes the whole system
- 24/7 coverage of 90% of your stack that means nothing when 10% goes bump in the night
- Two – or even three or four – teams, who cover a whole system 24/7 between them, but who can’t talk to each other or take ultimate responsibility.
Any of these issues – or myriad more – can cause huge impacts on your or your client’s revenue and reputation, and without a single team to get a handle on everything, they will come up.
So, how do you do ‘support’ in a world of increasingly complex tech stacks?

Now we’re getting somewhere!
To support a stack with over 20+ different integrated services you need a model very different from the traditional support set-up.
This is what people mean when they say full-stack support, and it’s what we offer as a third-party service to many agency partner including
It’s got to have a bird’s-eye view; take total ownership; ideally be tech-enabled; be 24/7; and of course actually have the depth and breadth of skills to resolve the incidents.
But what does that mean?
Bird’s-eye view
This kind of bleeds into tech-enabled, but isn’t totally the same point. Bird’s-eye view in this context means a single view of your entire system.
All of those services in your stack will have multiple monitoring options, all pumping out highly relevant data into different places. So your support needs some kind of platform for integrating these into a single view.
This is often achieved with a bespoke platform – in our case, we developed Mission Control (a platform that let’s us combine every feed into one place and manage incidents )- but this isn’t quite the same point as tech-enabled because there’s an organisational aspect too.
For a team to have a bird’s-eye view they must have a single ‘decision-making capacity’ with access to all that same info.
So a bird to view from its own eye, if you’ll allow a mixed, or perhaps blended, metaphor.
Ownership
Again bleeding – or blending – with the previous point, ownership incorporates a few ideas. That single omniscient team needs to:
- Take ultimate and full responsibility for any issue, whether it arises from infrastructure, code, a hybrid cloud problem – whatever.
- Have a robust incident management procedure (aka If the buck stops with you, you best know the price of a pint of milk). This team needs not only to see and tackle the issue but to have a standard, proven process. Every issue should have an (interactive) runbook and it should be followed wherever possible. This EXCLUDES waking up a developer in the middle of the night via the old phone-by-the-bed “support,” and includes actually having the skills to resolve any issue across the whole stack.
- Work against a tight SLA. The above two points – as well as response times and other important details – should be signed on the line that is dotted.
Tech-enabled
Tech enabled goes a little beyond a single bird’s-eye view. There’s a lot of variance in this point, but the essential idea is that it isn’t possible to support a whole stack without a fair bit of assistance.
Unless your team or partner or whoever is leaning heavily on tools which make communication, testing, and incident management a lot easier, they won’t be able to support you – is the takeaway.
Again, Mission Control is our answer – but there are others.
24/7
This one doesn’t change much in the context of full stack, but it’s worth pointing out that most 24/7 support services are anything but.
Just as a 24/7 garage SHOULD NOT entail banging on the glass to wake the sleeping attendant, and then waiting as he blearily fires up the till, 24/7 support SHOULD mean a person at their desk ready to jump on an issue whenever.
We achieve this by having teams in the UK, Singapore, US and Australia, but again, there are other options.
Although we recommend this vs. recruiting from r/DevelopersWithInsomnia
The takeaways:
- Stacks are getting bigger and more complex, this increases flexibility and functionality, but also (we’ll say somewhat redundantly) complexity, too.
- Complex stacks can’t be supported under the old model of support, especially not phone-by-the-bed support.
- To avoid the serious impacts on revenue and reputation that downtime can have, you need support that: has a bird’s-eye view, takes ownership of any issue and deals with the incident in a strategic, pre-defined way, is tech-enabled/has the right tools for the job, can do this all 24/7.
For support that fits that description, or for anything else, just get in touch.




